Web Scraping with Playwright and Firebase.
Learn how to Scrape data from your instagram page with Nodejs, Playwright and Firebase.
Prerequisites#
If you want to follow along this tutorial, you'll need the following:
- Basic Knowledge of Firebase and a Firebase account https://firebase.google.com/
- Basic knowledge of javascript
- A coding Editor Vscode Preferred
- API Development/Debugging tool.
What is web scrapping?#
Web scrapping refers to the extraction of data from a website. This information is collected and exported into a format (i.e csv) that is more useful to the user.
What is a Headless Browser?#
You might have heard of the term Headless Browser but still don't know what it means. You don't have to worry because the Internet's got our back 🙂
Headless browsers provide automated control of a web page in an environment similar to popular web browsers, but are executed via a command-line interface or using network communication. wikipedia.
Here are few most popular Headless Browsers 👇
Puppeteer: Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
Playwright: Playwright is a Node library developed by microsoft to automate Chromium, Firefox and WebKit with a single API. Playwright is built to enable cross-browser web automation that is ever-green, capable, reliable and fast.
Initial Setup 🚀#
Lets start off by initializing firebase cloud functions for javascript:
firebase init functions
cd functions
npm install playwright
This installs Playwright and browser binaries for Chromium, Firefox and WebKit. Once installed, you can require Playwright in a Node.js script and automate web browser interactions.
Now lets create our Instagram Scraper#
Instagram on the web uses React, which means we won’t see any dynamic content util the page is fully loaded. Playwright is available in the Clould Functions runtime, allowing you to spin up a Chrome/Firefox/Webkit browser on your server. It will render JavaScript and handle events just like the browser you’re using right now.
First, the function logs into a real instagram account. The page.type method will find the cooresponding DOM element and type characters into it. Once logged in, we navigate to a specific username and wait for the img tags to render on the screen, then scrape the src attribute from them.
const functions = require("firebase-functions");const playwright = require("playwright");exports.scrapeImages = functions.https.onRequest(async (req, res) => {// Randomly select a browser// You can also specify a single browser that you preferfor (const browserType of ["firefox", "chromium", "webkit"]) {console.log(browserType); // To know the chosen one 😁const browser = await playwright[browserType].launch();const context = await browser.newContext();const page = await context.newPage();await page.goto("https://www.instagram.com/accounts/login/");await page.waitForSelector("[type=submit]", {state: "visible",});// You can also take screenshots of pagesawait page.screenshot({path: `ig-sign-in.png`,});await page.type("[name=username]", "<your-username>"); // ->await page.type('[type="password"]', "<your-password>"); // ->await page.click("[type=submit]");await page.waitForSelector("[placeholder=Search]", { state: "visible" });await page.goto(`https://www.instagram.com/<your-username>`); // ->await page.waitForSelector("img", {state: "visible",});await page.screenshot({ path: `profile.png` });// Execute code in the DOMconst data = await page.evaluate(() => {const images = document.querySelectorAll("img");const urls = Array.from(images).map((v) => v.src);return urls;});await browser.close();console.log(data);// Return the data in form of jsonreturn res.status(200).json(data);}});
Replace highlighted fields with valid credentials.
Now we need to test out our API and to do that we're going to need an API debugging tool and I'd recommend Insomnia because it's the best API tool i've ever used and it has tons of features. You can also use tools like Postman.
start the dev server by running:
npm run serve
Open Insomnia and send a post request to the generated url from your firebase dev server.
Example http://localhost:5001/playwright-faecb/us-central1/scrapeImages
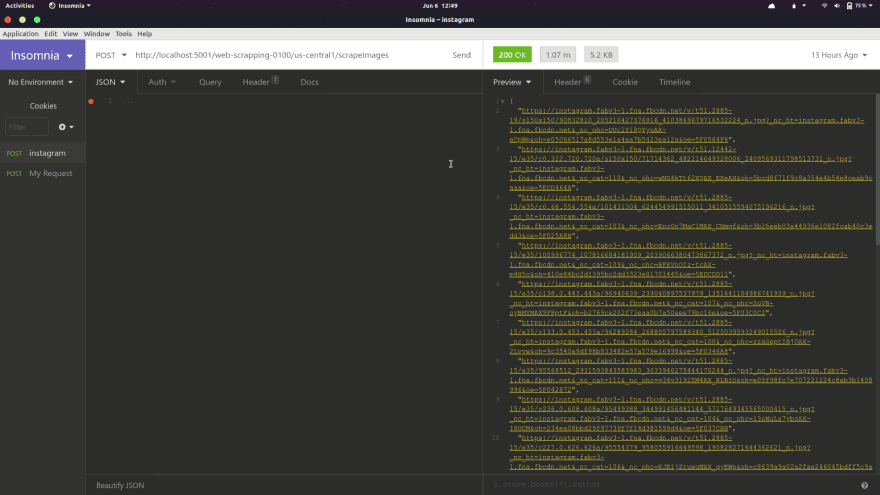
In the above image, you can see the response JSON data colored with yellow on the right side. It is an array of urls that points to individual images on your instagram page.
Lets reflect back step by step to better understand what we're doing.#
Playwright provides us with three different browser types so why not try three of them at the same time.
-
We loop through the three browser types
['chromium', 'firefox', 'webkit']. -
launch() We launch a new browser with the launch method.
-
newContext() Creates a new browser context. A Browser context provides us with most operations like creating a new tab in the browser.
-
goto method navigates to a specified URL path.
-
waitForSelector() waits for an element to either be or not be present in the browser.
-
screeshot() takes a screenshot of the current page.
-
text() provides us with the ability to fill out form fields.
-
click() allows us to click on an element or page in the dom.
-
evaluate(). You can do a lot in the callback of this function; However, we're just returning the
srcvalue of each image in the callback. -
browser.close() destroys our current browser as you already know.
You can do whatever you want with the data (Download the images) but in our case we are just logging it out on the console and returning it as a JSON string with a 200 response to see what it looks like.
Conclusion#
Most times Bad dudes applies this technique to Illegally extract data from a website and I'm pretty sure that the person reading this is not one of them.
Always remember to Use your code for good 🙂
Complete code: https://github.com/dnature/playwright-example
I hope you find this helpful.
Happy codding 💻 🙂